“ChatGPT is the most exciting advance in AI to date. It will fundamentally change our working patterns and environments, and the big tech ecosystem in which we operate. Understanding ChatGPT is a key requirement in 2023.”
– Martijn Theuwissen, COO of DataCamp
What is ChatGPT?
ChatGPT is an AI chatbot built on top of OpenAI’s GPT-3.5 & GPT-4 large language foundation models. GPT stands for Generative Pre-trained Transformer, which is a type of deep learning model able to generate human-like text, trained on a large dataset, and taking into account human feedback.
ChatGPT is an OpenAI product, as is DALL-E2, a product which can create, edit and adapt images based on text prompts. While ChatGPT is a web based interface allowing users to interact with GPT-3.5 & GPT-4, it’s also possible to connect to the OpenAI API to send automated test calls and responses direct to their GPT family of models. Multiple companies started doing this within months of its launch, such as Algolia, Reddit and Quizlet.
ChatGPT was launched to consumers on November 30 2022 as a prototype, based on GPT -3.5. Users can submit text prompts via a web interface and receive text based responses. Whilst not the only generative AI, currently ChatGPT is the most famous. It promises much in terms of assisting humans significantly in a wealth of day to day tasks. As Stephen Wolfram puts it:
“I myself have been deeply involved with the computational paradigm for many decades [..] And in doing this my goal has been to build a system that can “computationally assist”—and augment—what I and others want to do. I think about things as a human. But I can also immediately call on Wolfram Language and Wolfram|Alpha to tap into a kind of unique “computational superpower” that lets me do all sorts of beyond-human things.
It’s a tremendously powerful way of working. And the point is that it’s not just important for us humans. It’s equally, if not more, important for human-like AIs as well—immediately giving them what we can think of as computational knowledge superpowers, that leverage the non-human-like power of structured computation and structured knowledge.
We’ve just started exploring what this means for ChatGPT. But it’s pretty clear that wonderful things are possible.”
– “Wolfram|Alpha as the way to bring Computational Superpowers to ChatGPT”, Stephen Wolfram
How does ChatGPT work?
When you’re thinking about how to use ChatGPT and possible applications within your business, it is helpful to understand how GPT models work and the strengths and limitations of ChatGPT. Even if you’re not working directly on GPT applications, this is such an important development that everyone working in tech should have a basic understanding.
‘Do I need technical skills to be a product manager?’ No, but it makes sense to put some effort into understanding technical details at a basic level. How to use ChatGPT is one of those core technical skills product managers and anyone working in technology will need from on.
“Just as data literacy was a key corporate concern in the past years, AI literacy is now the new data literacy. Corporations worldwide are urgently looking to upskill workers in these new technologies.“
Martijn Theuwissen, COO of DataCamp
Caveat: we’re going to go through how ChatGPT works on its own, and then come to plugins.
It seemed only appropriate to ask ChatGPT to describe itself, which it did, very clearly:
“ChatGPT is a large language model that uses deep learning techniques to generate human-like responses to natural language prompts. The model is based on the GPT-3.5 architecture, which includes a transformer-based neural network with 175 billion parameters. ChatGPT was trained on a massive corpus of text data to develop an understanding of the nuances and patterns of natural language.
ChatGPT was fine-tuned using a reinforcement learning approach, where the model was trained to generate responses based on feedback from human users. Specifically, ChatGPT was trained to maximize a reward signal that was based on the quality of its responses, as judged by a human evaluator. This process involved generating a response to a prompt, receiving feedback from a human evaluator, and using that feedback to update the model’s parameters to improve future responses.
However, despite the sophistication of the model and the training methods used, there is still a risk of factual inaccuracies or hallucinations in ChatGPT’s responses. This is because the model’s training data is drawn from a vast and diverse range of sources, some of which may contain errors, biases, or misinformation. Additionally, the model’s fine-tuning process relies on human evaluators to provide feedback, which may not always be accurate or reliable.
To address these challenges, ChatGPT needs human assistance to function well. This includes ongoing monitoring and evaluation of the model’s responses to ensure that they are accurate and appropriate. It also involves providing the model with additional training data and feedback to improve its performance over time. Ultimately, the success of ChatGPT and other language models like it depends on a collaborative effort between humans and machines to develop sophisticated and nuanced language understanding capabilities.”
ChatGPT, 8th May 2023
Data Sources
Let’s take that piece by piece. First of all: the data the model uses to return answers. What is it? Is it live scraping or crawling? What’s the knowledge base feeding the model?
“There is a widespread misconception that OpenAI scoured the entire web, training as it went, when the truth is that there was a lot of data curation that went into preparing the data used for training and not all of it was done by OpenAI.”
“ChatGPT and DALL-E-2 — Show me the Data Sources”, Dennis Layton
The likely data sources for ChatGPT include
- A subset of Commoncrawl.org data: Common Crawl describes itself as ‘ a 501(c)(3) non-profit organisation dedicated to providing a copy of the internet to internet researchers, companies and individuals at no cost for the purpose of research and analysis’. In essence it crawls the internet in the same manner as search engine bots, but rather than keeping the data for private purposes as Google and Microsoft do, it makes it openly available
- Webtext2 data: outbound web pages from sites such as Reddit over a certain engagement threshold (i.e. 3 upvotes). So let’s say there was a page linked to in a Reddit post which got 27 upvotes. It could have been used to train the model. Multiple community sites seem to have been used in this way, on a paid and unpaid basis
- Two Internet books corpora and Wikipedia were also used
This is a sample of the internet, rather than the whole internet. Why? Because in developing these models better outcomes were realised by increasing the sophistication of the techniques used to learn natural language patterns used by the model, rather than the size of the dataset.
“In a nutshell, what has been learned over the last few years is that working with a smaller amount of high quality data with a larger model, often expressed in parameters, is a better way to go…Consider that GPT-2 and GPT-3 were trained on the same amount of text data, around 570GB, but GPT-3 has significantly more parameters than GPT-2, GPT-2 has 1.5 billion parameters while GPT-3 has 175 billion parameters. By increasing the number of parameters, the model is able to learn more complex patterns and structures of natural language, which allows it to generate more human-like text and understand natural language better.”
“ChatGPT and DALL-E-2 — Show me the Data Sources”, Dennis Layton
Data ChatGPT was trained on does not go beyond 2021. The model is not continuously taking in new datasets and learning from them if you are using it without plugins.
 What happened when we asked ChatGPT what product managers were saying about it
What happened when we asked ChatGPT what product managers were saying about it
Supervised and Reinforced learning
It’s important to understand the data sources to understand what sort of answers you might receive. And, as we’ll cover later, this also has pricing and legal ramifications.
However what ChatGPT does exceptionally is to respond well to humans, which it does by converting words into tokens (can be more than one per word), and then predicting token by token the best way to respond to a human prompt. This is why it sometimes makes up new words. To help it do this, it went through a human training stage.
“As a language model, it works on probability, able to guess what the next word should be in a sentence. To get to a stage where it could do this, the model went through a supervised testing stage.
Here, it was fed inputs, for example “What colour is the wood of a tree?”. The team has a correct output in mind, but that doesn’t mean it will get it right. If it gets it wrong, the team inputs the correct answer back into the system, teaching it correct answers and helping it build its knowledge. [Supervised learning]
It then goes through a second similar stage, offering multiple answers with a member of the team ranking them from best to worst, training the model on comparisons. [Reinforcement learning]”
“ChatGPT: Everything you need to know about OpenAI’s GPT-4 tool”, BBC Science Focus
It’s for this reason that ChatGPT contains a thumbs up, thumbs down input beside outputs and retains your chat history. Currently any interactions with ChatGPT are used to train the model by default, unless you disable chat history in your settings.
How to use ChatGPT: understanding the limitations
“GPT stands for Generative Pre-trained Transformer. Note that the “P” stands for “pre-trained.” You can’t take your dataset of user feedback and train GPT on it.”
“ChatGPT cannot do User Research”, Jason Godesky
When you’re thinking through how to use ChatGPT, understand that essentially ChatGPT is a model that is trying to generate a response to a human prompt that a human will accept as a good response based on the dataset it has available. ChatGPT works off a subset of internet text data gathered prior to September 2021. Some of that data is wrong, meaning it can give wrong information as answers. Secondarily it is trained by humans, and sometimes humans give bad instructions. Thirdly, its goal is to give a human a response that they accept. Most of the time it will give a right, and very good response. But some of the time it will confidently give a wrong response which can be difficult to detect:
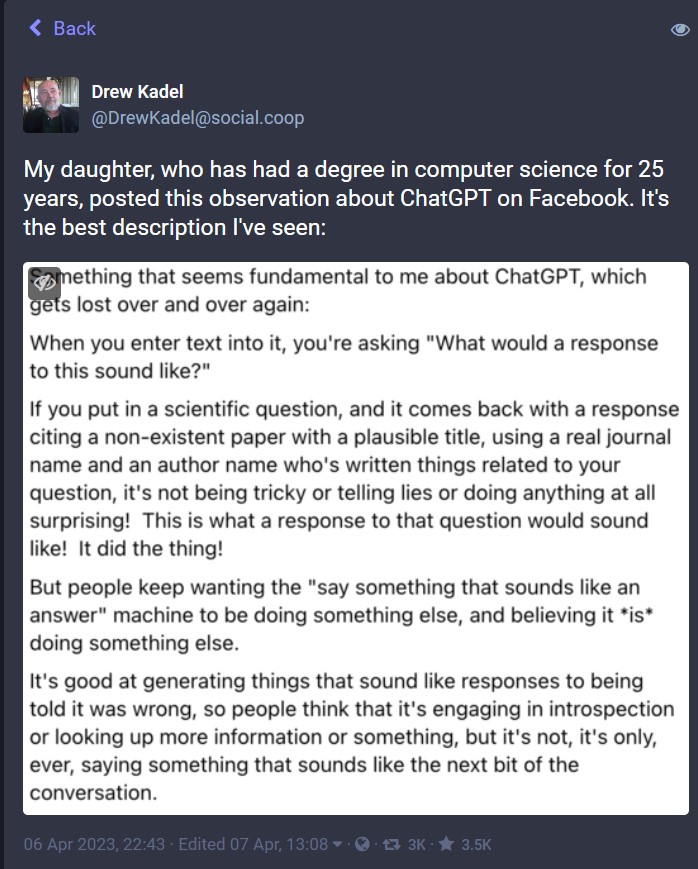 https://social.coop/@DrewKadel/110154048390452046
https://social.coop/@DrewKadel/110154048390452046
Worth knowing: The free version of ChatGPT is based on GPT-3.5, but an updated version of ChatGPT was released on March 14 2023 based on GPT-4, and is available on a paid-for basis to individual subscribers. GPT-4 improves on GPT-3.5 in a number of regards. It can describe images as well as text. Additionally answers have a higher likelihood of being factually accurate (more on this below) and the model demonstrates a higher ‘steerability’, which means it is better at adapting outputs to user requests (more on this below as well). The OpenAI API will be updated to GPT-4 in coming months, with waitlist access opened.. Having said that, paying for a subscription and accessing GPT-4 does not mean that your answers will automatically contain data from post 2021, or that they will be drastically more accurate. However as of May, if you have a ChatGPT Plus subscription and you toggle on web browsing in your settings, your responses will have access to up-to-date web data.
Other things ChatGPT doesn’t do
As Stephen Wolfram has explained if you want a calculation performed, such as the distance between Chicago and Toronto, “the kind of generalisation a neural net can readily do—say from many examples of distances between cities—won’t be enough; there’s an actual computational algorithm that’s needed.”
Remember that ChatGPT itself said that it was trained on a corpus of text data to “develop an understanding of the nuances and patterns of natural language.” Because it ‘speaks’ to us, and until this date, we have generally assumed that human brains outperform machines and we have generally assumed human language tasks were the most complex task for a machine to perform, there’s a tendency to see ChatGPT as a type of superhuman computer, and ascribe both natural language and computational abilities to it. However:
“while ChatGPT is a remarkable achievement in automating the doing of major human-like things, not everything that’s useful to do is quite so “human like”. Some of it is instead more formal and structured. And indeed one of the great achievements of our civilization over the past several centuries has been to build up the paradigms of mathematics, the exact sciences—and, most importantly, now computation—and to create a tower of capabilities quite different from what pure human-like thinking can achieve.”
“It’s completely remarkable that a few-hundred-billion-parameter neural net that generates text a token at a time can do the kinds of things ChatGPT can. And given this dramatic—and unexpected—success, one might think that if one could just go on and “train a big enough network” one would be able to do absolutely anything with it. But it won’t work that way. Fundamental facts about computation—and notably the concept of computational irreducibility—make it clear it ultimately can’t…
And yes, there’ll be plenty of cases where “raw ChatGPT” can help with people’s writing, make suggestions, or generate text that’s useful for various kinds of documents or interactions. But when it comes to setting up things that have to be perfect, machine learning just isn’t the way to do it—much as humans aren’t either.
And that’s exactly what we’re seeing in the examples above. ChatGPT does great at the “human-like parts”, where there isn’t a precise “right answer”. But when it’s “put on the spot” for something precise, it often falls down.”
“Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT”, Stephen Wolfram (all quotes in this section)
In short, ChatGPT acts well like a human, but it doesn’t act well like a computer. So that means that when asked a computational question (calculate xx / yy, or calculate the distance between xx city to yy city), if the answer isn’t in its data sources, and it doesn’t select it as the best answer in a response, it doesn’t answer it correctly. And at the most basic level, that is because it’s not what it’s trying to do. OpenAI were transparent about the model’s limitations when they announced ChatGPT, and it’s key to remember this when you’re thinking about how to use ChatGPT.
Implications of limitations
The limitations of the widely available versions has implications to adoption as of today. Due to taking off so swiftly as an adopted product worldwide, OpenAI have not only had to pivot strategy but other companies have had to pivot to adjust to it. For example, stackoverflow, a company where developers can ask technical questions and receive answers from the community, have banned ChatGPT on their site for now.
“Overall, because the average rate of getting correct answers from ChatGPT is too low, the posting of answers created by ChatGPT is substantially harmful to the site and to users who are asking and looking for correct answers.
The primary problem is that while the answers which ChatGPT produces have a high rate of being incorrect, they typically look like they might be good and the answers are very easy to produce. There are also many people trying out ChatGPT to create answers, without the expertise or willingness to verify that the answer is correct prior to posting. Because such answers are so easy to produce, a large number of people are posting a lot of answers. The volume of these answers (thousands) and the fact that the answers often require a detailed read by someone with at least some subject matter expertise in order to determine that the answer is actually bad has effectively swamped our volunteer-based quality curation infrastructure.”
stackoverflow; Temporary policy: ChatGPT is banned
This is exceptionally complicated: stackoverflow is one of the sources on which GPT-3 was trained. Therefore if fake information from ChatGPT posted on stackoverflow, this wouldn’t only erode stackoverflow’s business, but if this data was in future used to train a model, it would lead to widespread disinformation occurring by default, leading to a situation where ‘AI is eating itself’.
Solving the problem with plugins
Plug-ins form a partial solution to the problem of ChatGPT using and providing incorrect information from ChatGPT. If you’re thinking about how to use ChatGPT to source live information or to perform a computation, plug-ins can be a solution.
OpenAI is rolling out plug-ins gradually on a waitlist basis to a select group of users and developers, and of course, enterprises. Caveat: plugins do not totally solve the problem, but some of them reduce the recurrence significantly. Paying for ChatGPT should give you preferential waitlist access to plugins, which is currently one of the major benefits of doing it.
“OpenAI is adding support for plug-ins to ChatGPT — an upgrade that massively expands the chatbot’s capabilities and gives it access for the first time to live data from the web.
Up until now, ChatGPT has been limited by the fact it can only pull information from its training data, which ends in 2021. OpenAI says plug-ins will not only allow the bot to browse the web but also interact with specific websites, potentially turning the system into a wide-ranging interface for all sorts of services and sites.”
“OpenAI is massively expanding ChatGPT’s capabilities to let it browse the web and more”, the Verge
Currently there are only a limited number of plugins available, but they’re coming fast. They break down into plugins being developed by OpenAI themselves (sometimes in partnership with Microsoft, their biggest investor), and third party investors.
The latest release from OpenAI includes (in alpha mode) a web browser plugin allowing ChatGPT to retrieve up-to-date information from the web (leveraging work done by Microsoft on Bing), now additionally available as a setting in a ChatGPT plus subscription, and a code interpreter plugin, which can use Python to analyse datasets. (Python is a language; ChatGPT is good at language, and hence why this is a good solution to computational tasks).
Additionally Microsoft have just opened up access to the new Bing, which is both a web crawler and underpinned by ChatGPT. This makes Bing a good option for tasks which require up-to-date information.
However if you’re looking for ChatGPT to perform computational tasks, the major plug-in to understand is Wolfram Alpha, a third party plugin for ChatGPT. Wolfram drastically increases correct answers by making “ChatGPT smarter by giving it access to powerful computation, accurate math, curated knowledge, real-time data and visualization through Wolfram|Alpha and Wolfram Language.” Ben Thompson described it as “ChatGPT gets a computer”, or to put it another way:
“as an LLM neural net, ChatGPT—for all its remarkable prowess in textually generating material “like” what it’s read from the web, etc.—can’t itself be expected to do actual nontrivial computations, or to systematically produce correct (rather than just “looks roughly right”) data, etc. But when it’s connected to the Wolfram plugin it can do these things.”
“ChatGPT gets its “Wolfram Superpowers”!”, Stephen Wolfram
Applying understanding how ChatGPT works to product development work using ChatGPT
Do you know which version of ChatGPT you’re using, and are you using plug-ins? If the answer is no plug-ins, and the free version, and you want up-to-date and more accurate answers or computational powers then consider paying for a subscription and get on the waitlist for plugins (alternatively you can wait). If you just want live information from the web – buy a ChatGPT plus subscription and toggle on web browsing in settings or consider using Bing.
Can you fact check the outcomes: do you know if you’re being given a right or a wrong answer? If not, in the age of AI prompts, critical assessment of information and answers is a key skill to develop. Don’t accept what the machine tells you without thinking it through. Pause particularly if you are asking it a computational question.
Take a beat and consider the implications of spreading wrong information could have within your company. If you prioritise or focus on the wrong thing, that could have significant implications for your company’s competitiveness and resources. Think before you act. This goes for whether or not you are using plugins.
Individuals and ChatGPT
The short answer is currently: anyone as an individual, or on a consumer basis. All you have to do is to create an account and start asking questions.
However multiple companies have concerns about ChatGPT being used by employees or on their sites or systems, and it’s worth noting that ChatGPT is currently set up as a B2C / consumer product, i.e. it does not offer enterprise or B2B grade data security or privacy. It’s also a radically new product which raises many regulatory questions.
There are two major concerns beyond the possibility of it creating false information that could be used in company materials, code or decision making::
- Copyright infringement / concerns
- Data Privacy and Data Safety compliance
Copyright infringement by OpenAI and other LLMs
Earlier we covered some of the data sources for GPT-3. One of those was Reddit and one of those was stackoverflow. However, OpenAI did not pay for that data. The result of this is two-fold:
Copyright lawsuits and legislation
A class action lawsuit that accuses OpenAI of “software piracy on an unprecedented scale” has been filed in California and will be heard in May
Requests to legislators to strengthen copyright protections: 140k German content creators have submitted a letter to the EU requesting regulation and stronger copyright protections
Sites such as stackoverflow and Reddit are moving to charge for their data.
Has Wikipedia found a way to make money? As Ben Thompson at Stratechery notes, ‘One implication of this plug-in architecture is that someone needs to update Wikipedia’. Or to put it another way, data sources have just become very valuable in a set up where the success of AI depends on the accuracy of its retrieved responses; and where training data is underpinning blockbuster services being delivered by some of the most lucrative technology companies in the world.
Stackoverflow and Reddit have announced that they will move to charge for access to their community data, stating
“Reddit CEO Steve Huffman told The New York Times this week that he didn’t want to give a freebie to the world’s largest companies. “Crawling Reddit, generating value and not returning any of that value to our users is something we have a problem with,” he said.”
Online publishers are following suit. All of this will increase the costs of building and running large LLMs in the future, which is going to in turn impact end consumer costs in the short term before the cost of building these models comes down.
Twitter have also raised prices for access to their data, with Elon Musk threatening to sue OpenAI.
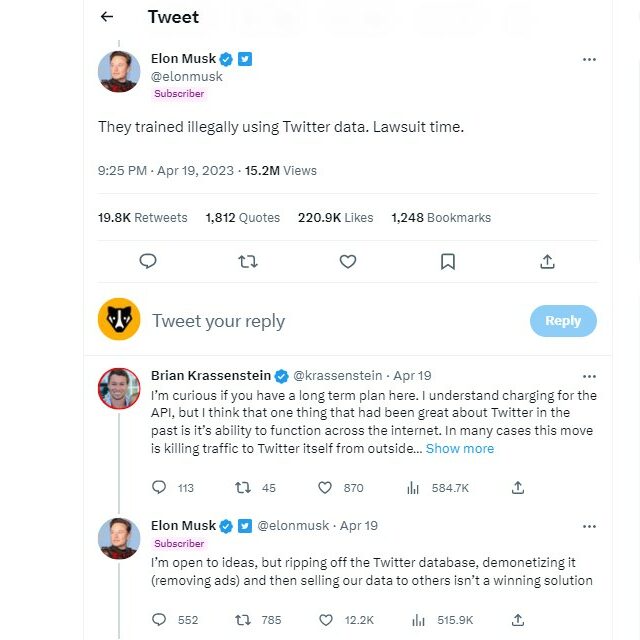 https://twitter.com/elonmusk/status/1648784955655192577
https://twitter.com/elonmusk/status/1648784955655192577
Besides that there is the thorny question of: let’s say ChatGPT wrote this article (it didn’t). Does OpenAI own the copyright or does Hustle Badger?
Open AI and Data Privacy and Data Safety compliance
We’ve covered that by default and unless you adapt your privacy settings, your prompts are being used to train ChatGPT. This is true even if you’re a paying customer of OpenAI.
The issues being looked into on the consumer side so far are:
- Inaccurate information
- Failing to disclose data protection practices
- Processing personal data without sufficient legal justification
- Insufficient protections for children on the platform
- Data security – since in mid March OpenAI had a data breach, where some users were able to see titles from other users’ chat history
In short, there’s a lot of worry about consumer data protection. As a result, ChatGPT has been temporarily banned in Italy, Canada is conducting a privacy investigation, and multiple other EU countries, including Germany, are also taking a look.
In addition there are concerns around the training data used and whether it contained personally identifiable information.
A common problem for companies is employees asking ChatGPT to analyse and process proprietary company data or sensitive user data. This represents a data breach for corporations. It’s for this reason that Samsung and multiple finance and consulting companies have banned the use of ChatGPT.
How to use ChatGPT day to day: applying privacy issues to use cases for the tool
In terms of product management day to day work, there have been a slew of posts and articles suggesting that product managers leverage ChatGPT to perform calculations, or to use it to summarise company meetings, or to use it to review user data. Clearly, given the limitations ChatGPT has doing computations, and the data protection issues, this isn’t necessarily a good idea.
You need to think carefully about how to use ChatGPT before using ChatGPT, because using ChatGPT is sharing data with it. And you need to be especially careful about sharing company or user data. Ask your company what their policy is and abide by it. The risks of getting things wrong here are significant.
There are lots of great use cases for product management work outside these types of use cases, which we’ll be delving into in a later article in the series.
How to use ChatGPT: Summary
When using ChatGPT and OpenAI products, it’s good to understand how they work. Arguably it’s going to be key in navigating this new landscape, and understanding will assist with day to day practical use of the tools and with discussing product and service development within your company.
Be alert to inaccurate information, limitations, biases and risks around data and your company. Think before you share company or personal information (especially if not your own) with ChatGPT and other LLMs. Understand your company policy regarding use of ChatGPT before putting company materials, user data or company data into the tool. If you have permission to share data or perform tasks, and it suits your use case, consider using plug-ins or beta features in Plus.
Resources
Note: this article was authored in early May 2023. This is a fast moving space and while we will endeavour to keep this up to date, out of date statements are inevitable. Please keep us honest at contact@hustlebadger.com
FAQs
Who owns ChatGPT?
OpenAI, a San Francisco based AI company, own ChatGPT. OpenAI have received significant investment capital from Microsoft, and it’s rumoured that Microsoft have a 49% share in the company, giving them considerable stake and sway.
What does ChatGPT stand for?
ChatGPT stands for Chat, meaning speak to, or interact with a chat bot, GPT (Generative Pre-trained Transformer), which is the term given to the family of large language models underpinning ChatGPT. Generative means it predicts tokens, or words, on the basis of training data, probabilities and training weights given by its transformer architecture.
How to use ChatGPT?
Go to https://chat.openai.com/ and create an account, then ask a question. However: it’s key to be aware of how ChatGPT works in order to use it well. There’s a guide here. In addition, it’s a good idea to be aware of how it processes data and if using it for user or company data purposes, ask what your company policy is around using ChatGPT, and abide by it. You can also access ChatGPT through multiple Microsoft products, such as Bing search engine and CoPilot.